Small Language Models: KI für die Hosentasche

Samsung hat kürzlich angekündigt, dass das Galaxy S26 vollständig auf On-Device-KI setzen wird, ohne Cloud-Abhängigkeit. Das klingt nach einer Randnotiz in einer Pressemitteilung, ist aber ein Signal für einen fundamentalen Wandel: Die Zukunft der KI liegt nicht nur in immer größeren Modellen, sondern auch in immer kleineren. Small Language Models (SLMs) sind der stille Gegenentwurf zum GPT-Gigantismus, und sie verändern gerade, was KI auf Endgeräten leisten kann.
Die Zahlen sind bemerkenswert. Microsofts Phi-4-Mini hat nur 3,8 Milliarden Parameter, übertrifft aber bei mathematischem Reasoning Modelle, die zwanzigmal größer sind. Googles Gemma 3n läuft mit dem Speicherbedarf eines 2-Milliarden-Parameter-Modells, obwohl es technisch 5 Milliarden Parameter hat. Diese Modelle brauchen keine Rechenzentren, keine Internetverbindung, keine Cloud-Abonnements. Sie laufen auf dem Gerät, das man in der Hand hält.
Was Small Language Models ausmacht
Die Definition von »klein« ist relativ. Im Kontext von Sprachmodellen gelten Systeme mit weniger als etwa 10 Milliarden Parametern als SLMs. Zum Vergleich: GPT-4 hat geschätzt über eine Billion Parameter, Claude 3.5 bewegt sich im dreistelligen Milliardenbereich. Ein SLM ist also nicht wirklich klein, nur kleiner.
Der entscheidende Unterschied liegt nicht in der absoluten Größe, sondern in der Architektur und den Optimierungen. SLMs werden von Anfang an für Effizienz gebaut. Sie nutzen Techniken wie Quantisierung, bei der die Präzision der Zahlen reduziert wird, um den Speicherbedarf um bis zu 75 Prozent zu senken. Sie verwenden Pruning, das Entfernen von Neuronen und Verbindungen, die wenig zum Ergebnis beitragen. Und sie profitieren von Destillation, einem Verfahren, bei dem ein kleineres »Schüler«-Modell trainiert wird, die Antworten eines größeren »Lehrer«-Modells zu imitieren.
Das Ergebnis sind Modelle, die auf Smartphones, Tablets, Laptops und sogar eingebetteten Systemen laufen können, ohne dass man einen High-End-Server im Keller braucht.
Die aktuellen Spitzenreiter
Googles Gemma-Familie ist derzeit die vielseitigste Option für On-Device-KI. Gemma 3n, veröffentlicht 2025, ist das erste multimodale On-Device-Modell von Google: Es verarbeitet nicht nur Text, sondern auch Bilder, Audio und Video. Die »selective parameter activation« sorgt dafür, dass nur die jeweils benötigten Teile des Modells aktiv sind, was den Speicherbedarf drastisch reduziert. Mit Unterstützung für über 140 Sprachen ist es auch für globale Anwendungen geeignet.
Microsoft hat mit der Phi-Familie einen anderen Schwerpunkt gesetzt: Reasoning. Phi-4 mit 14 Milliarden Parametern schlägt bei komplexen mathematischen Aufgaben Modelle, die ein Vielfaches größer sind, wurde im Januar 2025 als Open Source auf Hugging Face veröffentlicht. Im Februar 2025 folgten Phi-4-multimodal, das Sprache, Bilder und Text gleichzeitig verarbeiten kann, sowie Phi-4-mini für textbasierte Aufgaben. Der größte Durchbruch kam im Mai 2025 mit der Phi-4-Reasoning-Familie: Phi-4-reasoning, Phi-4-reasoning-plus und Phi-4-mini-reasoning fügen explizite Denkfähigkeit hinzu. Diese Modelle übertreffen trotz ihrer geringen Größe OpenAI o1-mini und DeepSeek-R1-Distill-Llama-70B bei den meisten Benchmarks.
Aus der Open-Source-Community kommt SmolLM3-3B von Hugging Face, das bei Benchmarks Llama-3.2-3B und Qwen2.5-3B übertrifft. Qwen3-0.6B von Alibaba ist eines der meistgeladenen Modelle auf Hugging Face und zeigt, dass selbst unter einer Milliarde Parameter brauchbare Ergebnisse möglich sind. Google hat außerdem Gemma 3 270M veröffentlicht, ein ultra-kompaktes Modell mit nur 270 Millionen Parametern, das auf aufgabenspezifisches Fine-Tuning optimiert ist, sowie Gemma 3 1B, das bei nur 529 MB Größe bis zu 2.585 Tokens pro Sekunde verarbeitet.
Warum »auf dem Gerät« wichtig ist
Die Vorteile von On-Device-KI gehen über Bequemlichkeit hinaus.
Da ist zunächst die Privatsphäre. Wenn ein Sprachmodell lokal läuft, verlassen die Daten das Gerät nicht. Keine Anfrage an einen Server, keine Speicherung in der Cloud, keine Analyse durch Dritte. Für Anwendungen im Gesundheitswesen, im Finanzsektor oder einfach für Menschen, die ihre Privatsphäre schätzen, ist das ein entscheidender Vorteil. Die Compliance mit Datenschutzverordnungen wie GDPR oder CCPA wird erheblich einfacher, wenn sensible Daten das Gerät gar nicht erst verlassen.
Dann ist da die Latenz. Eine Anfrage an einen Cloud-Server braucht Zeit, Millisekunden bis Sekunden, je nach Verbindung und Serverlast. Ein lokales Modell antwortet sofort. Für Anwendungen, die Echtzeitreaktionen erfordern, von Sprachassistenten bis zur Fahrzeugsteuerung, kann dieser Unterschied kritisch sein.
Schließlich die Verfügbarkeit. Cloud-KI setzt eine Internetverbindung voraus. On-Device-KI funktioniert auch im Flugzeug, im Tunnel, in Gebieten mit schlechter Abdeckung. Das macht sie ideal für mobile Anwendungen und IoT-Geräte, die nicht immer online sein können.
Die technischen Grenzen
SLMs sind keine Wunderwaffe. Sie haben echte Einschränkungen, die man kennen sollte.
Die offensichtlichste: Sie wissen weniger. Ein Modell mit 3 Milliarden Parametern kann nicht dasselbe Weltwissen speichern wie eines mit 100 Milliarden. Bei Fragen, die breites Allgemeinwissen erfordern, sind große Modelle im Vorteil.
Komplexe Reasoning-Ketten sind schwieriger. Obwohl Modelle wie Phi-4 bei mathematischen Aufgaben glänzen, stoßen sie bei vielschichtigen, mehrstufigen Problemen an Grenzen. Die Faustregel: Je länger und verschachtelter eine Argumentationskette sein muss, desto mehr profitiert man von größeren Modellen.
Der Kontextfenster ist oft kleiner. Während GPT-4 und Claude 3.5 Kontextfenster von über 100.000 Tokens unterstützen, sind SLMs typischerweise auf 8.000 bis 32.000 Tokens beschränkt. Für lange Dokumente oder komplexe Codebases kann das ein Problem sein.
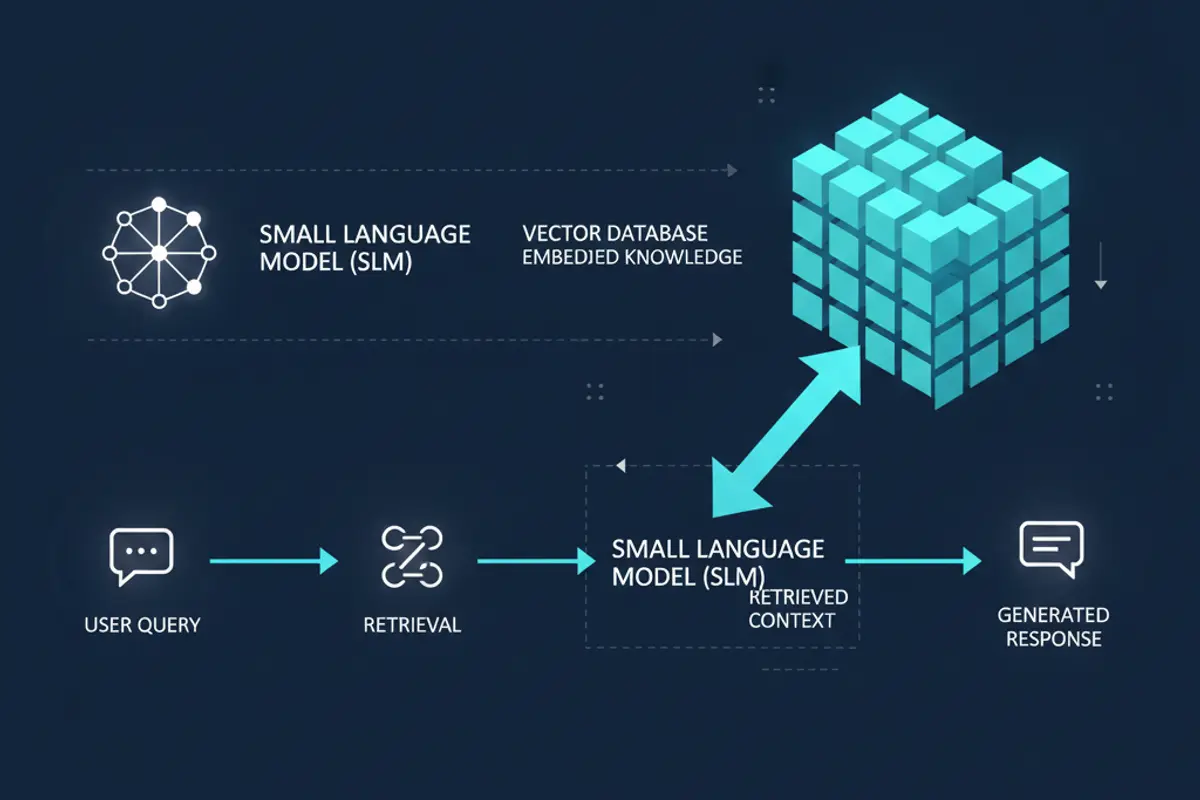
Retrieval Augmented Generation: Der Multiplexer
Eine Technik mildert viele dieser Einschränkungen: Retrieval Augmented Generation (RAG). Statt alles Wissen im Modell selbst zu speichern, wird eine externe Datenbank mit relevanten Informationen gekoppelt. Wenn eine Frage gestellt wird, sucht das System zuerst in der Datenbank nach passenden Dokumenten und gibt diese als Kontext an das Modell weiter.
Google AI Edge hat kürzlich robuste Unterstützung für On-Device-RAG eingeführt. Das erlaubt es, ein kleines Modell mit anwendungsspezifischen Daten zu erweitern, ohne das Modell selbst neu trainieren zu müssen. Ein Kundenservice-Bot kann so auf die Produktdokumentation zugreifen, ein persönlicher Assistent auf Kalender und E-Mails, ein Recherche-Tool auf eine lokale Wissensdatenbank.
Wohin die Reise geht
Die Prognosen sind eindeutig: Der Markt für Small Language Models wird von 0,93 Milliarden Dollar 2025 auf 5,45 Milliarden Dollar 2032 wachsen, ein jährliches Wachstum von fast 29 Prozent. Bis 2025 werden schätzungsweise 75 Prozent aller Unternehmensdaten am Edge verarbeitet, also auf lokalen Geräten statt in zentralen Rechenzentren.
Samsung erwartet, dass der Erfolg des Galaxy S26 einen »RAM-Krieg« in der Smartphone-Industrie auslösen wird. Wenn On-Device-Modelle anspruchsvoller werden, steigt der Bedarf an Arbeitsspeicher. 24 oder 32 Gigabyte RAM könnten bald zum Standard für Flaggschiff-Geräte werden.
Die technische Entwicklung geht in mehrere Richtungen gleichzeitig. Modelle werden effizienter, Hardware wird leistungsfähiger, Komprimierungstechniken werden ausgefeilter. Das Ergebnis: Was heute auf einem High-End-Laptop läuft, wird in zwei Jahren auf einem Mittelklasse-Smartphone laufen.
Für Entwickler und Unternehmen bedeutet das: Die Entscheidung zwischen Cloud und Edge wird flexibler. Einfache Aufgaben, die Privatsphäre erfordern oder geringe Latenz brauchen, können lokal laufen. Komplexe Aufgaben, die Zugang zu aktuellem Wissen oder starkes Reasoning erfordern, können weiterhin in der Cloud verarbeitet werden. Die intelligentesten Systeme werden beides kombinieren, mit einem kleinen Modell auf dem Gerät, das entscheidet, wann es die große Schwester in der Cloud ruft.
Die Demokratisierung der KI ist nicht nur eine Frage der Kosten, sondern auch der Architektur. Small Language Models bringen Intelligenz dorthin, wo sie gebraucht wird: in die Hosentasche.
KI-Agenten: Die autonome Revolution hat begonnen
KI-Agenten arbeiten autonom, planen selbstständig und nutzen Werkzeuge. Wie die neue Generation auto
Video-KI im Vergleich: Sora, Runway, Veo und Kling im Test
Sora 2, Runway Gen-4.5, Google Veo 3.1 oder Kling? Wir vergleichen die führenden Video-KI-Tools nach