RAG erklärt: So wird KI faktentreu
Wenn ChatGPT ein Gerichtsurteil erfindet oder Claude eine Studie zitiert, die nicht existiert, liegt das an einer fundamentalen Eigenschaft von Sprachmodellen: Sie wissen nicht, was sie nicht wissen. Sie raten, auch wenn sie nicht raten sollten. Retrieval Augmented Generation, kurz RAG, ist die Antwort der Industrie auf dieses Problem, und 2025 ist es zum Standard für Unternehmensanwendungen geworden.
Laut Databricks nutzen bereits 60 Prozent ihrer Large-Language-Model-Implementierungen RAG. Eine aktuelle Studie zeigt, dass 73 Prozent aller RAG-Implementierungen in großen Organisationen stattfinden. Der Grund ist einfach: RAG macht KI vertrauenswürdig, indem es sie mit echten Daten füttert, statt sie raten zu lassen.
Wie RAG funktioniert
Das Grundprinzip ist elegant: Bevor ein Sprachmodell eine Antwort generiert, wird es mit relevanten Informationen aus einer externen Datenbank versorgt. Statt sich auf sein Trainingswissen zu verlassen, das veraltet oder lückenhaft sein kann, arbeitet das Modell mit frischen, verifizierten Daten.
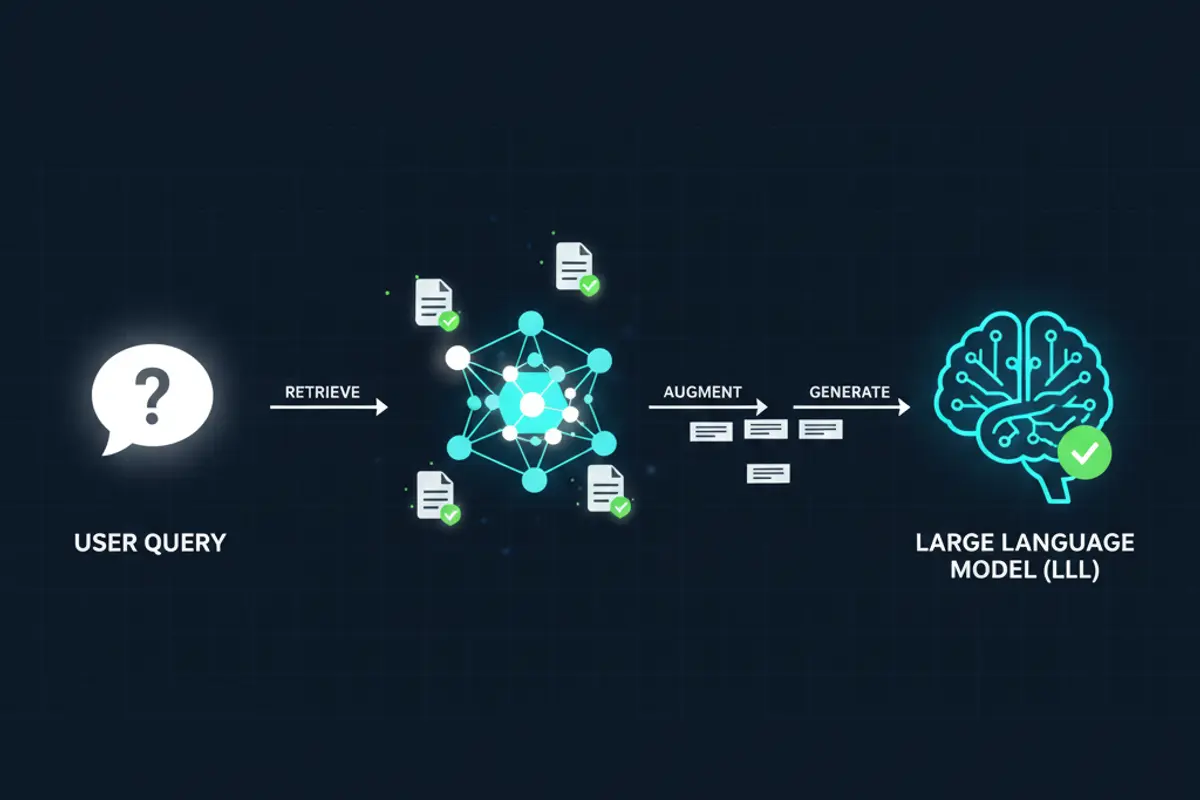
Der Prozess läuft in drei Phasen ab: Retrieve, Augment, Generate.
In der Retrieve-Phase wird die Nutzeranfrage in eine mathematische Repräsentation umgewandelt, einen sogenannten Embedding-Vektor. Dieser Vektor wird gegen eine Datenbank von Dokumenten abgeglichen, die ebenfalls als Vektoren gespeichert sind. Die ähnlichsten Dokumente werden abgerufen.
In der Augment-Phase werden die gefundenen Dokumente als Kontext zur ursprünglichen Anfrage hinzugefügt. Das Sprachmodell erhält also nicht nur die Frage, sondern auch relevante Hintergrundinformationen.
In der Generate-Phase erzeugt das Modell seine Antwort auf Basis des erweiterten Kontexts. Es kann auf die bereitgestellten Quellen verweisen, Zitate einbauen, und seine Aussagen mit den abgerufenen Dokumenten belegen.
Embeddings und Vektordatenbanken
Das Herzstück von RAG sind Embeddings, numerische Repräsentationen von Text, die semantische Ähnlichkeit erfassen. Moderne Embedding-Modelle erzeugen Vektoren mit 768, 1536 oder sogar 3072 Dimensionen. Texte mit ähnlicher Bedeutung liegen im Vektorraum nahe beieinander, auch wenn sie unterschiedliche Wörter verwenden.
Vektordatenbanken wie Pinecone, Weaviate, Qdrant oder Milvus sind spezialisiert auf die Speicherung und Suche dieser hochdimensionalen Vektoren. Sie nutzen Indexstrukturen wie Hierarchical Navigable Small World (HNSW) Graphen, die Ähnlichkeitssuchen in logarithmischer Zeit ermöglichen, selbst bei Milliarden von Dokumenten. Quantisierungstechniken komprimieren die Vektoren um bis zu 75 Prozent, ohne die Suchqualität wesentlich zu beeinträchtigen.
Die Ähnlichkeit zwischen Vektoren wird typischerweise mit Kosinus-Ähnlichkeit gemessen, die den Winkel zwischen Vektoren berechnet. Für normalisierte Vektoren, wie sie die meisten Embedding-Modelle produzieren, ist das äquivalent zur euklidischen Distanz.
Chunking: Die Kunst der Dokumentzerlegung
Ein kritischer, oft unterschätzter Schritt ist das Chunking, also die Zerlegung von Dokumenten in kleinere Einheiten. Ein 100-seitiges PDF kann nicht als Ganzes in den Kontext eines Sprachmodells passen. Es muss in handhabbare Stücke zerlegt werden.
Die naive Methode, Dokumente einfach in 512-Token-Blöcke zu schneiden, funktioniert schlecht. Bessere Ansätze respektieren die Dokumentstruktur: Überschriften, Absätze, Abschnitte. Wenn ein Chunk aus dem Abschnitt »Installationsschritte« stammt, sollte diese Information mitgespeichert werden, damit das Retrieval-System den Kontext versteht.
Typische Chunk-Größen liegen zwischen 256 und 1024 Tokens, mit Überlappungen von 50 bis 200 Tokens, um Informationen an Chunk-Grenzen nicht zu verlieren. Die optimale Größe hängt vom Anwendungsfall ab: Längere Chunks bewahren mehr Kontext, kürzere ermöglichen präziseres Retrieval.
Fortgeschrittene Techniken: 2025 und darüber hinaus
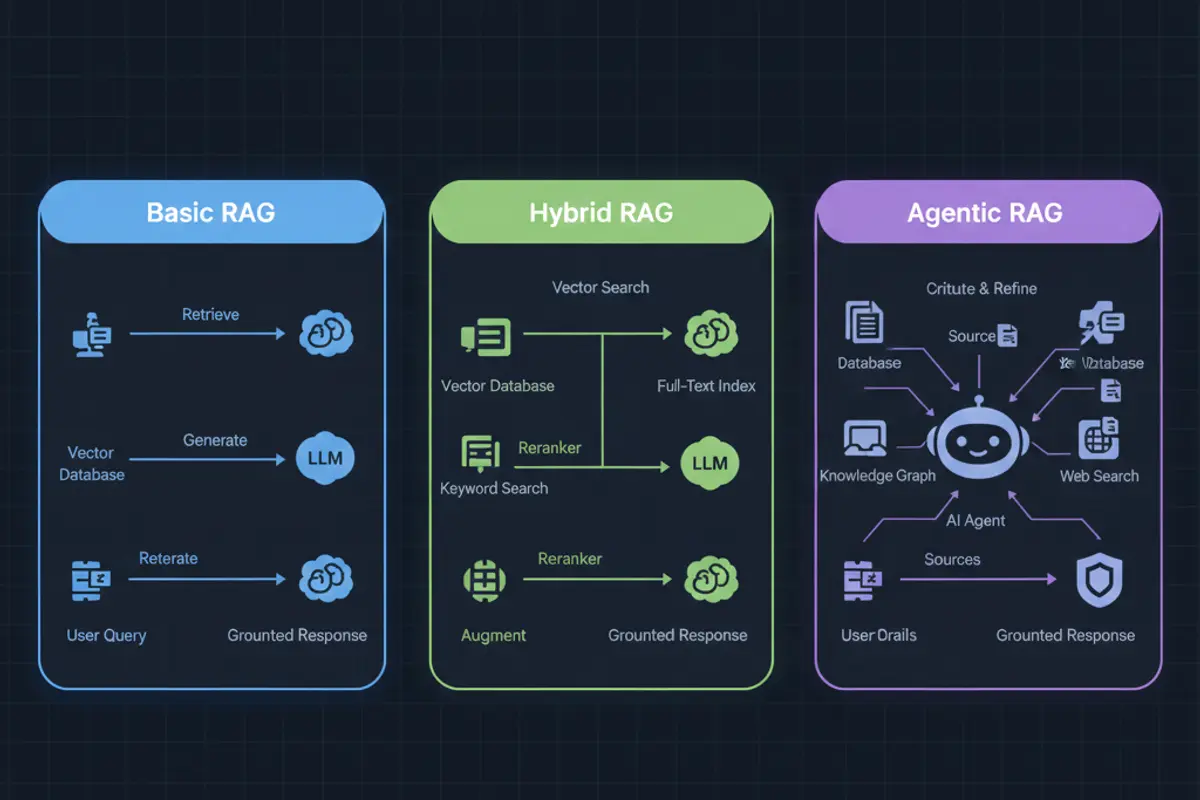
RAG hat sich 2025 erheblich weiterentwickelt. Einfache Vektor-Suche ist nur der Anfang.
Hybrid Search kombiniert Vektorsuche mit klassischer Keyword-Suche. Manche Anfragen brauchen semantisches Verständnis (»Wie installiere ich die Software?«), andere exakte Treffer (»Fehlermeldung XYZ«). Hybride Systeme liefern für beide Fälle gute Ergebnisse.
Reranking fügt eine zweite Stufe hinzu: Ein spezialisiertes Modell bewertet die abgerufenen Dokumente und sortiert sie nach Relevanz. Das verbessert die Qualität erheblich, besonders wenn die initiale Suche viele Kandidaten zurückgibt.
Self-Reflective RAG nutzt »Reflection Tokens«, um die eigenen Retrievals kritisch zu bewerten. Das Modell fragt sich: Ist dieses Dokument wirklich relevant? Reicht der Kontext für eine fundierte Antwort? Studien zeigen, dass dieser Ansatz Halluzinationen um bis zu 52 Prozent reduziert.
Corrective RAG (CRAG) löst das Problem veralteter Daten: Wenn die lokale Wissensbasis nicht ausreicht, triggert das System automatisch Web-Suchen, um aktuelle Informationen einzuholen.
Agentic RAG geht noch weiter: Autonome Agenten planen mehrstufige Retrieval-Strategien, wählen zwischen verschiedenen Datenquellen, und iterieren, bis sie eine befriedigende Antwort gefunden haben.
GraphRAG: Beziehungen verstehen
Eine besonders vielversprechende Entwicklung ist GraphRAG, das Wissensgraphen mit RAG kombiniert. Traditionelles RAG behandelt Dokumente als isolierte Einheiten. GraphRAG erfasst zusätzlich die Beziehungen zwischen Entitäten: Person A arbeitet bei Firma B, Produkt C gehört zu Kategorie D, Vorfall E wurde durch Ursache F ausgelöst.
Diese relationalen Informationen ermöglichen Multi-Hop-Queries: »Welche Produkte wurden von Kunden beanstandet, die auch Produkt X gekauft haben?« erfordert mehrere Verknüpfungen, die reines Vektor-Retrieval nicht leisten kann. Graph-Datenbanken wie Neo4j mit ihrer nativen Unterstützung für Beziehungsabfragen werden zum Backend für diese Anwendungsfälle.
RAG vs. Fine-Tuning: Wann was?
RAG ist nicht die einzige Methode, um Sprachmodelle mit Domänenwissen auszustatten. Fine-Tuning, also das Nachtrainieren des Modells auf spezifischen Daten, ist die Alternative. Beide Ansätze haben ihre Berechtigung.
RAG eignet sich, wenn Wissen häufig aktualisiert wird, wenn Transparenz über Quellen wichtig ist, wenn Halluzinationsrisiken minimiert werden müssen, und wenn die Kosten für kontinuierliches Training zu hoch wären. Ein Kundenservice-Bot, der auf aktuelle Produktdokumentation zugreifen muss, ist ein klassischer RAG-Anwendungsfall.
Fine-Tuning eignet sich, wenn das Modell einen bestimmten Stil oder Tonfall annehmen soll, wenn strukturierte Ausgaben wie JSON erforderlich sind, wenn tiefes Domänenverständnis nötig ist, und wenn die Wissensbasis stabil ist. Ein spezialisierter medizinischer Assistent, der komplexe diagnostische Reasoning-Patterns beherrschen muss, profitiert von Fine-Tuning.
Die beste Lösung ist oft ein Hybrid: Fine-Tuning für Domänenkompetenz und Ausgabeformat, RAG für aktuelle Daten und Quellenbelege. Dieser Ansatz wird manchmal RAFT genannt, Retrieval-Augmented Fine-Tuning.
Praktische Empfehlungen
Für Unternehmen, die RAG implementieren wollen, haben sich einige Best Practices etabliert.
Investieren Sie in Datenqualität. RAG ist nur so gut wie die Dokumente, auf die es zugreift. Schlecht strukturierte, veraltete oder widersprüchliche Dokumente führen zu schlechten Antworten.
Implementieren Sie Fallback-Mechanismen. Wenn das Retrieval keine relevanten Dokumente findet, sollte das System das kommunizieren, statt zu halluzinieren. Confidence-Scores und Abstention-Schwellen sind kritisch.
Denken Sie an Sicherheit. In regulierten Branchen müssen personenbezogene Daten geschützt, Zugriffe protokolliert, und Compliance-Anforderungen erfüllt werden. RAG-Systeme brauchen robuste Zugriffskontrollen.
Messen Sie die Retrieval-Qualität. Nicht nur die finale Antwort zählt, sondern auch, ob die richtigen Dokumente gefunden wurden. Separate Metriken für Retrieval-Precision und Antwortqualität helfen bei der Optimierung.
RAG ist keine Magie, aber es ist der derzeit beste Weg, Sprachmodelle mit Fakten zu verankern. In einer Welt, in der KI-Halluzinationen reale Konsequenzen haben können, ist das keine Kleinigkeit.
KI-Halluzinationen: Wenn Maschinen Fakten erfinden
Warum erfinden KI-Modelle Fakten? Von erfundenen Gerichtsurteilen bis zur OpenAI-Forschung: Ursachen
KI-Kosten und Umwelt: Der versteckte Preis der künstlichen Intelligenz
Energieverbrauch, CO2-Emissionen, Wasserverbrauch: Die ökologischen Kosten von KI und was dagegen ge