Prompt Engineering: Die Kunst der KI-Kommunikation
Als Anthropic eine Stelle als »Prompt Engineer and Librarian« mit einem Gehalt von bis zu 335.000 Dollar ausschrieb, wurde die Tech-Welt aufmerksam. Das war 2023. Zwei Jahre später ist die Frage, ob Prompt Engineering eine eigenständige Karriere bleibt oder zu einer Basisfähigkeit wird, die jeder braucht, noch nicht beantwortet. Was feststeht: Die Fähigkeit, effektiv mit KI-Modellen zu kommunizieren, ist 2025 wertvoller denn je.
Prompt Engineering ist keine Magie und kein Glücksspiel. Es ist eine systematische Methode, um präzise, kreative und verlässliche Ergebnisse aus Sprachmodellen zu erzielen. Die meisten Fehler entstehen nicht durch Modellbeschränkungen, sondern durch unklare Anweisungen.
Die Grundprinzipien
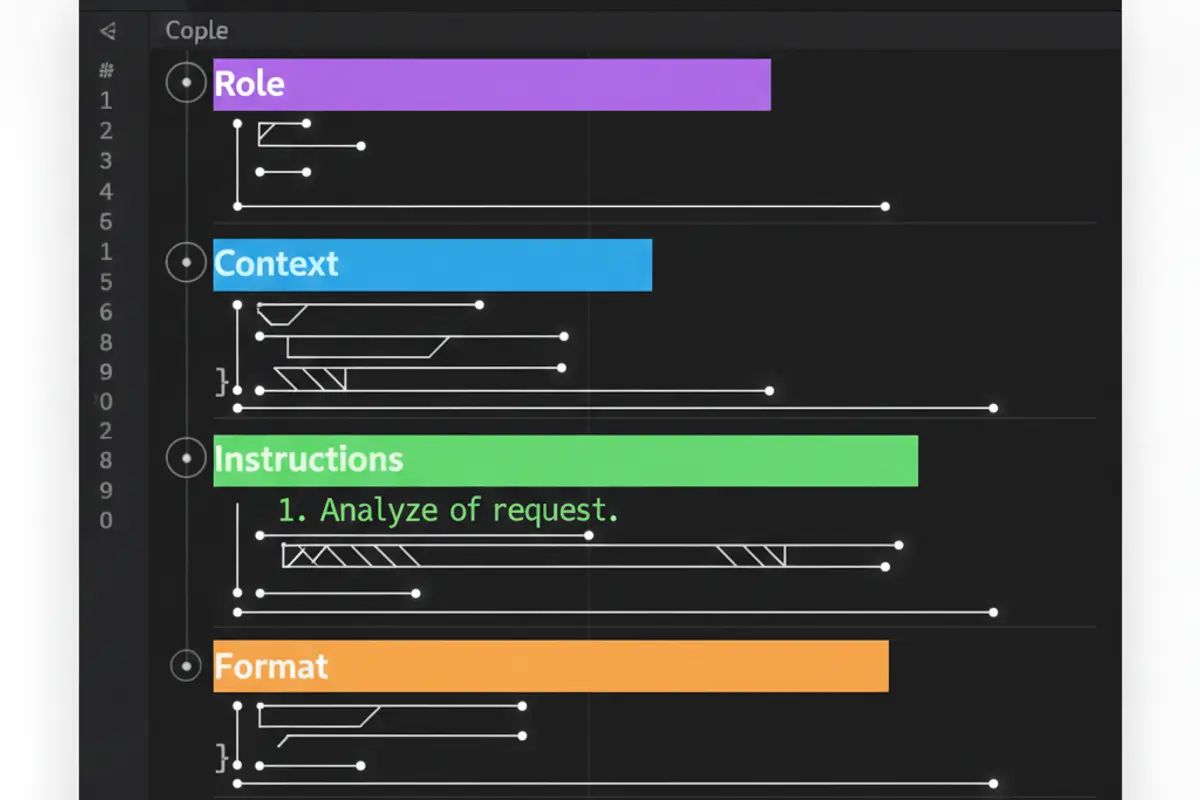
Klare Struktur und Kontext sind wichtiger als clevere Formulierungen. Ein effektiver Prompt hat mehrere Komponenten: eine Rollenzuweisung, die den Kontext setzt; klare Anweisungen, was das Modell tun soll; relevante Hintergrundinformationen; und eine Spezifikation des gewünschten Ausgabeformats.
Ein einfaches Beispiel: Statt »Schreib mir einen Blogpost über KI« ist »Du bist ein Tech-Journalist mit Fokus auf KI für ein deutschsprachiges Fachpublikum. Schreibe einen 800-Wort-Artikel über die Entwicklung von Reasoning-Modellen 2025. Struktur: Einleitung, drei Hauptabschnitte, Fazit. Tonfall: informativ, aber zugänglich« erheblich effektiver.
Die Rollenzuweisung funktioniert, weil sie dem Modell einen Rahmen gibt. Ein »erfahrener Python-Entwickler« wird anderen Code schreiben als ein »Anfänger, der gerade Python lernt«. Die Persona aktiviert relevantes Wissen und Schreibstil.
Chain-of-Thought und andere Techniken
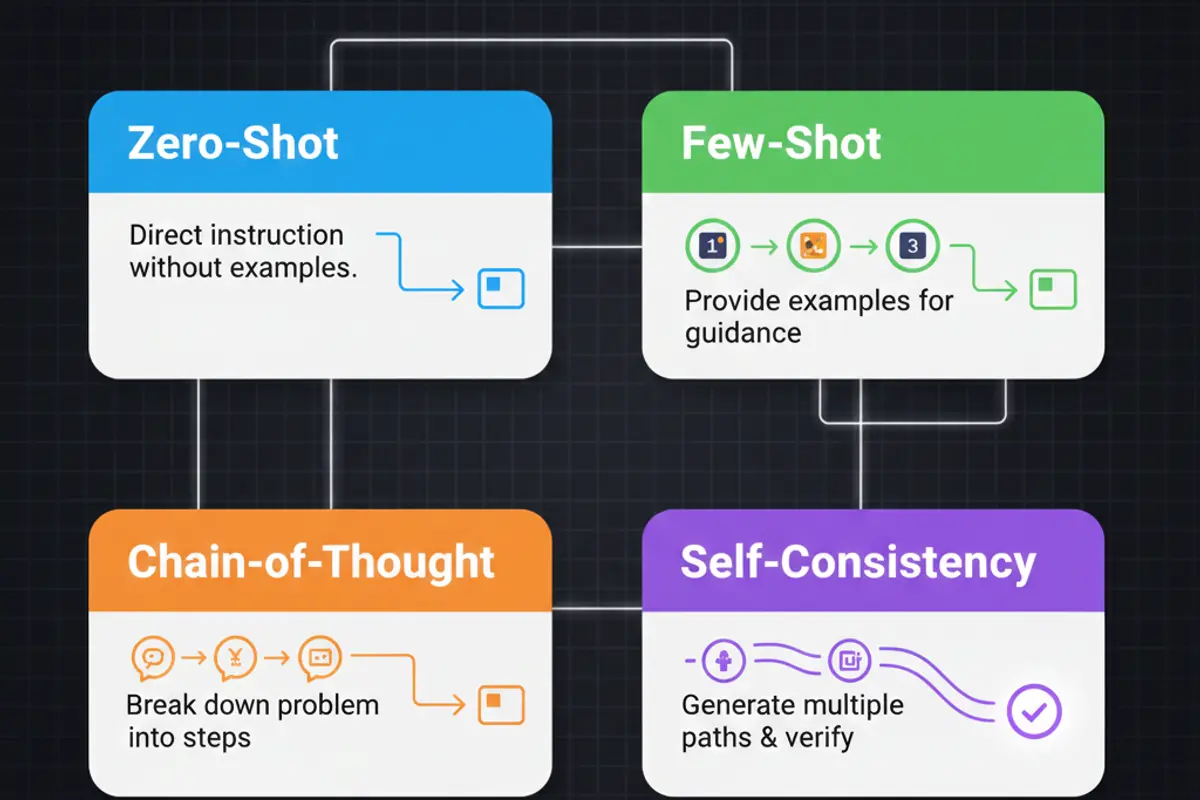
Chain-of-Thought (CoT) Prompting ist eine der wirkungsvollsten Techniken für komplexe Aufgaben. Statt das Modell direkt nach einer Antwort zu fragen, fordert man es auf, seinen Denkprozess Schritt für Schritt zu zeigen. Der einfachste Weg: »Lass uns das Schritt für Schritt durchdenken.«
Die Forschung zeigt: Wenn Modelle ihre Reasoning-Schritte explizit formulieren, machen sie weniger Fehler bei mathematischen Problemen, logischen Schlussfolgerungen und mehrstufigen Aufgaben. Das gilt besonders für komplexe Fragen, bei denen die direkte Antwort oft falsch wäre.
Few-Shot Prompting ergänzt Anweisungen durch Beispiele. Statt zu erklären, wie das Ausgabeformat aussehen soll, zeigt man es. Claude 4 und GPT-5 achten sehr genau auf Details in Beispielen, daher sollten diese exakt das gewünschte Verhalten demonstrieren. Für die meisten Aufgaben reichen zwei bis drei Beispiele.
Self-Consistency erweitert Chain-of-Thought: Das gleiche Problem wird mehrfach mit dem gleichen Prompt gelöst, und die häufigste Antwort wird gewählt. Das transformiert einzelne Reasoning-Versuche in ein robustes Verifikationssystem.
Prompt Chaining zerlegt komplexe Aufgaben in kleinere Schritte, wobei die Ausgabe eines Prompts zum Input des nächsten wird. Das erhöht die Latenz durch mehrere API-Aufrufe, verbessert aber oft dramatisch Genauigkeit und Zuverlässigkeit.
Modellspezifische Unterschiede
Nicht alle Modelle reagieren gleich. Claude 4.x folgt Anweisungen präziser als frühere Generationen, neigt aber bei Opus 4.5 zu Overengineering: mehr Dateien, mehr Abstraktion, mehr Flexibilität als angefordert. Die Lösung: explizit minimale Lösungen verlangen.
GPT-5 verwendet intern eine Verbosity-Skala von 1 bis 10, mit 3 als Standard. Man kann die Ausführlichkeit durch einfache Anweisung ändern. Das System-Prompt von GPT-5 ist auf Produktivität und Pragmatismus ausgerichtet, während Claude's auf Vorsicht und Designprinzipien setzt.
Ein wichtiger Unterschied: Claude ist angewiesen, Fragen nicht mit Lob zu beginnen. »Das ist eine großartige Frage« entfällt. Das Modell antwortet direkt auf den Inhalt. Wer dieses Verhalten erwartet, sollte es explizit anfordern.
Temperature ist ein kritischer Parameter. Höhere Werte (0.7-1.0) erzeugen kreativere, aber weniger konsistente Ausgaben. Für faktische Aufgaben wie Datenextraktion oder Q&A ist Temperature 0 optimal.
Halluzinationen reduzieren
Relevante Daten im Kontext geben dem Modell eine faktische Grundlage. Explizite Erlaubnis, »Ich weiß es nicht« zu sagen, reduziert erfundene Antworten. Chain-of-Thought hilft, weil es das Modell zwingt, seine Arbeit zu zeigen, was Fehler sichtbar macht.
Eine oft unterschätzte Technik: Das Modell auffordern, Quellen für Behauptungen zu nennen. Kann es keine nennen, ist die Behauptung verdächtig. In Kombination mit RAG, also dem Abruf externer Dokumente, lassen sich Halluzinationen drastisch reduzieren.
Werkzeuge und Workflows
Prompt Engineering hat sich professionalisiert. LangChain orchestriert komplexe LLM-Workflows. PromptLayer bringt Git-ähnliche Versionskontrolle für Prompts. Promptfoo ermöglicht Unit-Tests für Prompts. Helicone bietet Observability und Prompt-Management. Guardrails AI definiert Schemas und Constraints für Modellausgaben.
Der Begriff »PromptOps« beschreibt die neue operative Disziplin: Prompt-Lifecycle-Management mit Linting, Token-Optimierung, Lasttests und Observability. Erfolgreiche Teams behandeln Prompts wie Code: mit Sorgfalt geschrieben, mit Tests validiert, mit Versionierung dokumentiert.
Die Zukunft der Fähigkeit
Ob Prompt Engineer ein eigenständiger Job bleibt, ist umstritten. Microsofts Chief Marketing Officer für KI sagt: »Vor zwei Jahren dachte jeder, Prompt Engineer wird der heiße Job. Aber man braucht nicht mehr den perfekten Prompt.« Eine Microsoft-Umfrage zeigt, dass Unternehmen Prompt Engineer als zweitniedrigste Priorität bei neuen Rollen einordnen.
Die Gegenposition: Die Fähigkeit wird nicht obsolet, sie wird zur Basiskompetenz. Wie Lesen und Schreiben gehört Prompting zu dem, was jeder Wissensarbeiter beherrschen sollte. Die Gehälter für spezialisierte Prompt Engineers liegen weiterhin zwischen 90.000 und 200.000 Dollar, mit Spitzenwerten darüber.
Die Wahrheit liegt vermutlich dazwischen. »Prompt Engineer« als isolierter Jobtitel mag verschwinden. Die Kompetenz, effektiv mit KI-Systemen zu kommunizieren, wird Teil vieler Rollen, von Entwicklern über Analysten bis zu Marketing-Spezialisten. Der Unterschied zwischen jemandem, der KI gut nutzt, und jemandem, der es nicht tut, liegt oft in wenigen Zeilen Text.