KI-Halluzinationen: Wenn Maschinen Fakten erfinden

Ein Anwalt in New York reichte 2023 einen Schriftsatz ein, der sechs Gerichtsurteile als Präzedenzfälle zitierte. Das Problem: Keines dieser Urteile existierte. ChatGPT hatte sie erfunden, komplett mit Aktenzeichen, Richternamen und plausibel klingenden Rechtsausführungen. Der Fall wurde zum Symbol für ein Phänomen, das die KI-Branche seitdem beschäftigt: Halluzinationen.
OpenAI hat im Herbst 2025 eine Forschungsarbeit veröffentlicht, die das Problem von Grund auf neu erklärt. Die zentrale These: Sprachmodelle halluzinieren, weil ihre Trainings- und Bewertungsverfahren Raten belohnen, statt Unsicherheit einzugestehen. Das klingt technisch, hat aber weitreichende Konsequenzen für jeden, der KI-Systeme nutzt.
Warum KI-Modelle Dinge erfinden
Ein Sprachmodell wie GPT-4 oder Claude wurde auf Milliarden von Texten trainiert. Es hat gelernt, Muster zu erkennen und fortzusetzen. Wenn man es fragt »Wer war der erste Mensch auf dem Mond?«, erkennt es das Muster und antwortet korrekt. Aber wenn man es fragt »Wer war der dritte Mensch auf dem Mond, der einen roten Hut trug?«, erkennt es ein ähnliches Muster und produziert eine ähnlich strukturierte Antwort, auch wenn die Frage Unsinn ist.
Das Problem liegt in den Anreizen während des Trainings. Modelle werden belohnt, wenn sie Antworten geben, die plausibel klingen und den Erwartungen entsprechen. Sie werden nicht belohnt, wenn sie sagen »Das weiß ich nicht« oder »Diese Frage ergibt keinen Sinn«. Im Gegenteil: Unsicherheit wird oft als Schwäche gewertet. Also raten die Modelle lieber, als zuzugeben, dass sie keine Ahnung haben.
Anthropic hat 2025 mit Interpretierbarkeitsforschung einen anderen Aspekt beleuchtet. Die Forscher fanden in Claude interne Schaltkreise, die normalerweise verhindern, dass das Modell antwortet, wenn es keine ausreichenden Informationen hat. Halluzinationen treten auf, wenn diese Hemmung fehlerhaft aufgehoben wird, etwa wenn das Modell einen Namen erkennt, aber nicht genug über die Person weiß, und dann plausibel klingende, aber falsche Details erfindet.
Wie häufig sind Halluzinationen?
Die Zahlen variieren stark je nach Aufgabe und Modell. Bei alltäglichen Anfragen liegen die Halluzinationsraten zwischen 2,5 und 8,5 Prozent. Das klingt akzeptabel, bis man bedenkt, dass bei medizinischen Fragen Raten von 80 bis 90 Prozent gemessen wurden und bei komplexen Recherche-Aufgaben bis zu 94 Prozent.
Die Qualität der Trainingsdaten macht einen messbaren Unterschied. Laut einer MIT-Studie von 2025 zeigen Modelle, die auf sorgfältig kuratierten Datensätzen trainiert wurden, 40 Prozent weniger Halluzinationen als solche, die auf rohen Internetdaten trainiert wurden. Das erklärt zum Teil, warum neuere Modelle tendenziell besser abschneiden, obwohl sie das Problem nicht gelöst haben.
Was man dagegen tun kann
Die Branche hat mehrere Strategien entwickelt, um Halluzinationen zu reduzieren.
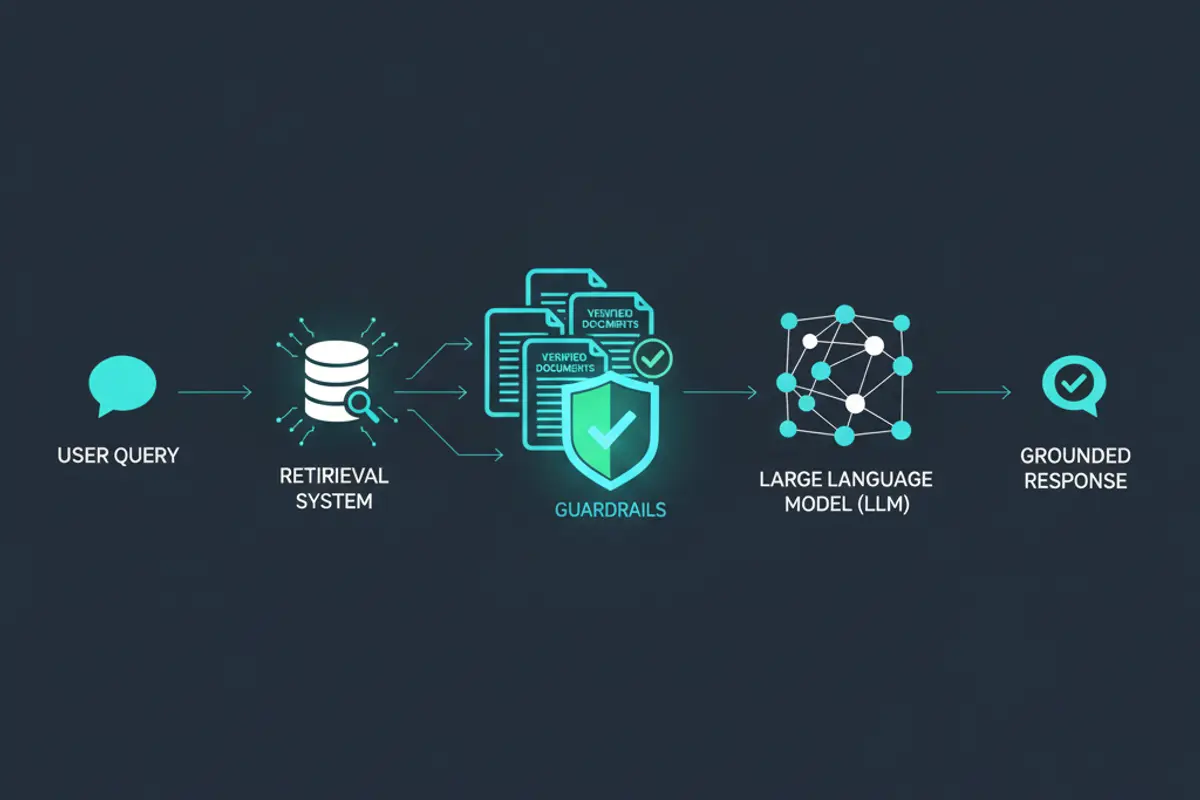
Die wichtigste ist Retrieval Augmented Generation (RAG). Statt sich auf das im Modell gespeicherte Wissen zu verlassen, wird bei jeder Anfrage eine externe Datenbank durchsucht und die gefundenen Informationen als Kontext mitgegeben. Das Modell antwortet dann auf Basis dieser verifizierten Quellen statt auf Basis von Mustern in seinen Trainingsdaten. Studien zeigen, dass RAG Halluzinationen um 42 bis 68 Prozent reduzieren kann. Bei medizinischen Anwendungen mit Zugang zu vertrauenswürdigen Quellen wie PubMed wurden Genauigkeitsraten von 89 Prozent erreicht.
Prompt Engineering hilft ebenfalls. Chain-of-Thought-Prompting, bei dem das Modell aufgefordert wird, seinen Denkweg schrittweise zu erklären, reduziert Fehler bei komplexen Reasoning-Aufgaben. Die explizite Aufforderung, Unsicherheit einzugestehen, kann das Modell dazu bringen, ehrlicher zu antworten.
Guardrails sind automatisierte Prüfsysteme, die Antworten gegen verifizierte Datenbanken abgleichen, bevor sie an den Nutzer weitergegeben werden. Kann eine Behauptung nicht validiert werden, wird sie markiert oder unterdrückt. Eine Stanford-Studie von 2024 fand, dass die Kombination von RAG, Reinforcement Learning from Human Feedback (RLHF) und Guardrails Halluzinationen um 96 Prozent reduzieren kann.
Die Grenzen der Lösungen
Keine dieser Methoden ist perfekt. RAG funktioniert nur so gut wie die Datenbank, auf die es zugreift. Wenn die Quelle veraltet, unvollständig oder selbst fehlerhaft ist, werden diese Fehler weitergegeben. Und das Modell kann Informationen aus verschiedenen Dokumenten auf irreführende Weise kombinieren.
Ein subtileres Problem: RAG löst das Halluzinationsproblem nicht architekturell. Das Modell hat keine eingebaute Fähigkeit, Wahrheit von Erfindung zu unterscheiden. Es produziert nur Text, der zu den Eingaben passt. Wenn die Eingaben (die abgerufenen Dokumente) mehrdeutig oder widersprüchlich sind, kann das Modell trotzdem halluzinieren.
Praktische Konsequenzen
Für Nutzer bedeutet das: KI-generierte Inhalte müssen verifiziert werden, besonders bei Faktenbehauptungen. Das gilt für juristische Recherchen ebenso wie für medizinische Informationen, historische Daten oder technische Dokumentation. Die Modelle sind nützliche Werkzeuge, aber keine verlässlichen Quellen.
Für Entwickler bedeutet es, dass Halluzinationsmanagement Teil jeder ernsthaften KI-Anwendung sein muss. Ein System ohne Guardrails, ohne Quellenanbindung, ohne Möglichkeit der Verifikation ist ein Haftungsrisiko.
Die Branche hat aufgehört, von »Null Halluzinationen« zu sprechen. Das Ziel ist jetzt, Unsicherheit messbar und vorhersagbar zu machen. Ein Modell, das sagt »Ich bin mir zu 60 Prozent sicher«, ist nützlicher als eines, das falsche Informationen mit Überzeugung vorträgt. Diese Verschiebung, von Allmacht zu kalibrierter Bescheidenheit, ist vielleicht der wichtigste Fortschritt in der KI-Sicherheit der letzten Jahre.
KI in der Wissenschaft: Wie künstliche Intelligenz Forschung revolutioniert
Von AlphaFold über KI-Co-Wissenschaftler bis zu selbstfahrenden Laboren: Wie KI wissenschaftliche En
RAG erklärt: So wird KI faktentreu
Retrieval Augmented Generation (RAG) macht KI vertrauenswürdig. Wie RAG funktioniert, wann es sinnvo